What Are SPLDs?
A Simple Programmable Logic Device (SPLD) is a compact electronic component used to perform logic functions in electronic systems. It is known for its straightforward structure and ability to retain configurations even without power. In this article, you'll learn about SPLD, its comparisons with other devices, its features, and how its models work.Catalog

Introduction to SPLD
A Simple Programmable Logic Device (SPLD) is a type of integrated circuit designed to carry out a variety of logic operations. While similar to a Complex PLD (CPLD), an SPLD typically comes with fewer input/output pins and programmable elements. This makes it more power-efficient and simpler in structure.
To configure an SPLD, you’ll often need a specific programming device. Manufacturers may have their unique methods for programming these devices, so the process can vary. Despite this, one common feature of SPLDs is that they are non-volatile. This means they can keep their configuration intact even when the power is turned off.
Inside an SPLD, you’ll find a collection of programmable logic gates and points, which enable it to perform different tasks. Many SPLDs also include memory elements and flip-flops, adding to their versatility in creating both logic and memory-based designs.
Comparison of SPLD with Other PLDs
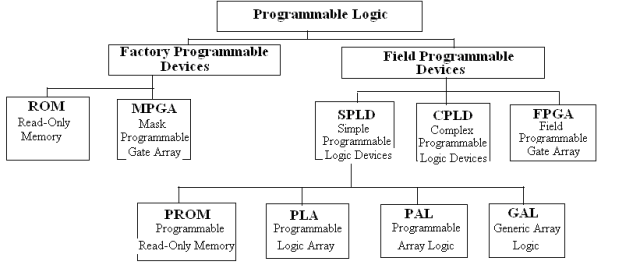
Programmable Logic Devices (PLDs) are a broad category that includes several types of devices such as Programmable Read-Only Memory (PROM), Erasable Programmable Read-Only Memory (EPROM), Programmable Logic Array (PLA), Programmable Array Logic (PAL), and Generic Array Logic (GAL). Each type is designed with unique structural features and functions, as summarized in the table below.
The structure of a PLA shares similarities with a PROM. Both have an arrangement of AND gates, OR gates, and output buffers. However, the AND gate array in a PLA is programmable, offering more flexibility. When building the same logic functions, PLAs typically use fewer cells in the AND and OR gate arrays compared to PROMs, making them more efficient for certain applications.
PAL devices, on the other hand, sometimes include a registered output structure. This allows them to handle both combinational and sequential logic tasks, making them suitable for a wider range of designs. GAL devices take versatility a step further with their programmable macro-logic units, which offer various operational modes. These modes can replicate the different output structures found in PAL devices.
While programming PAL and GAL devices can be complex due to the need for dedicated tools and programming languages, these tools are designed to be user-friendly. This makes working with PAL and GAL devices accessible, even with their advanced capabilities.
Overview of Atmel SPLD
Atmel SPLD products, such as the 16V8 and 22V10, are designed to meet industry standards and offer a range of options for different power and voltage requirements. These include low-voltage, zero-power, and quarter-power versions, catering to a variety of needs. Atmel also provides the "L" series devices, which feature automatic power-down functionality, making them highly energy-efficient. A popular example is the ATF22LV10CQZ, a battery-friendly option.
Atmel SPLDs are available in a proprietary TSSOP package, which is one of the smallest designs for SPLD devices. They also support other commonly used packaging formats, ensuring compatibility with various systems. All Atmel SPLD products are built using EE technology, ensuring reliable performance and repeatable programming. Additionally, they are supported by widely available third-party programming tools, making them easy to work with.
Understanding SPLD Models

SPLD models are designed to focus on diversity within samples by ensuring that selected samples are as varied as possible. This diversity is based on the idea that samples within the same group or cluster tend to be more similar to each other compared to those from different groups. This clustering approach helps capture a wide range of behaviors and patterns in the data.
For example, in a video recognition task, frames from the same video are considered part of the same cluster due to their similarities. On the other hand, frames from different videos exhibit diversity because they belong to different clusters. This concept applies to SPLD, where the data set is divided into clusters, and the system assigns values to samples based on their diversity within these groups.
The model introduces a parameter matrix that distributes the learning weights across multiple clusters. This ensures that selected samples cover a broad spectrum of data rather than being concentrated in one cluster. It allows SPLDs to balance between simplicity (assigning weights to easy samples) and variety (choosing from multiple groups).
A unique feature of SPLD is its use of an objective function that promotes diversity through a method called negative L2,1 norm. Unlike traditional SPLs that may focus on a few clusters, SPLD encourages spreading sample selection across as many clusters as possible. This creates a richer learning experience by avoiding redundancy.
SPLD optimization follows a step-by-step approach, alternating between updating two sets of parameters. By ranking samples based on their loss values and applying a gradually decreasing threshold, SPLD ensures that it includes a mix of samples, ranging from simpler to more complex. This process ensures a diverse and balanced selection, which sets SPLD apart from traditional SPL methods.
Optimization Process in SPLD

The optimization process in SPLD focuses on refining how samples are chosen and distributed across clusters. It aims to balance diversity and learning effectiveness by solving a non-convex optimization problem. This is achieved through an objective function:
Here:
The function is designed to minimize loss while encouraging a diverse sample selection using two parameters, and . These control the balance between focusing on simpler samples and ensuring diversity.
Since data is often grouped into clusters, the optimization problem is broken into smaller sub-problems. Each cluster has its own optimization task:
Here, represents the loss for the -th sample in cluster . The solution ensures that each cluster contributes a diverse set of samples to the overall learning process.
To further refine the selection process, samples are ranked based on their loss. A threshold, determined by the parameters and , adjusts dynamically as more samples are selected:
If a sample’s loss satisfies , it is selected (); otherwise, it is not ().
The optimization alternates between updating and , ensuring that each step refines the parameters to achieve better results. By incorporating a decreasing threshold, SPLD includes samples with higher loss over time, ensuring a mix of simpler and more challenging examples. This method improves learning efficiency while maintaining sample diversity.
This structured approach, coupled with precise mathematical definitions, makes SPLD effective for complex, heterogeneous data scenarios.
About us
ALLELCO LIMITED
Read more
Quick inquiry
Please send an inquiry, we will respond immediately.

What Is SRAM?
on January 14th

ADM699AR Analog Devices Alternatives, Features, Applications
on January 14th
Popular Posts
-

Complex Instruction Set Computers: How They Changed Computing?
on April 18th 147749
-

USB-C Pinout and Features
on April 18th 111904
-
Using Xilinx Unified Simulation Primitives: A Comprehensive Guide to FPGA Design and Simulation
on April 18th 111349
-

Power Supply Voltages in Electronics: Meaning of VCC, VDD, VEE, VSS, and GND
on April 18th 83714
-

RJ45 Connector Guide: Pinout, Wiring, Cable Types, and Uses
on January 1th 79502
-

The Ultimate Guide to Wire Color Codes in Modern Electrical Systems
The way our electrical systems use colors isn’t just for looks. Each wire color now indicates a specific function, making it easier to identify and handle electrical components correctly during ins...on January 1th 66869
-

Quality (Q) Factor: Equations and Applications
The quality factor, or 'Q', is important when checking how well inductors and resonators work in electronic systems that use radio frequencies (RF). 'Q' measures how well a circuit minimizes energy...on January 1th 63004
-

Purge Valve Guide: Function, Symptoms, Testing, and Replacement for Optimal Engine Performance
The purge valve is a key part of a car’s system that helps keep the air clean by managing fuel vapors before they can escape into the atmosphere. This not only helps the environment by reducing pol...on January 1th 62942
-

Achieving Peak Performance with the Maximum Power Transfer Theorem
The Maximum Power Transfer Theorem explains how energy from a source, such as a battery or generator, flows to a connected load. It shows the exact condition where the load receives the most power....on January 1th 54076
-

A23 Battery Specifications and Compatibility
The A23 battery is a small, cylinder-shaped battery with high voltage. Also called 23A, 23AE, or MN21, it runs at 12 volts and much higher than AA or AAA batteries. Its special design make...on January 1th 52087
HOT Part Number
-

LTC4063EDD#TRPBF
Analog Devices Inc.
IC BATT CHG LI-ION 1CELL 10DFN
MIMX8MM1CVTKZAA
NXP USA Inc.
IC MPU I.MX 8M MINI SOLOLITE
APDS-9005-020
Broadcom Limited
SENSOR OPT 500NM AMB 6CHIPLED
06031A820KAT2A
KYOCERA AVX
CAP CER 82PF 100V C0G/NP0 0603
ICM-20602
TDK InvenSense
IMU ACCEL/GYRO/TEMP I2C/SPI LGA
170M4611
Eaton - Bussmann Electrical Division
FUSE SQUARE 350A 700VAC RECT
08053C105JAZ2A
KYOCERA AVX
CAP CER 1UF 25V X7R 0805
EP1C12F324C6N
Intel
IC FPGA 249 I/O 324FBGA
2SC4617T1G
onsemi
TRANS NPN 50V 0.1A SC75 SOT416
TL431AILPRAG
onsemi
IC VREF SHUNT ADJ 1% TO92-3
ADAU1787BCBZRL
Analog Devices Inc.
4 ADC, 2 DAC LOW POWER CODEC, AU
74VHC164MTCX
onsemi
IC SHIFT REGISTER 8BIT 14TSSOP
DAN222M3T5G
onsemi
DIODE ARRAY GP 80V 100MA SOT723
NR3015T470M
Taiyo Yuden
FIXED IND 47UH 300MA 1.608OHM SM
MM3Z18VC
onsemi
DIODE ZENER 18V 200MW SOD323F
1N4001W
Rectron USA
DIODE GEN 1A 50V SOD-123F
SMBJ90A
Taiwan Semiconductor Corporation
TVS DIODE 90VWM 146VC DO214AA
NTA1215MC
Murata Power Solutions Inc.
DC DC CONVERTER +/-15V 1W -

SDR1307-101KL
Bourns Inc.
FIXED IND 100UH 1.9A 180MOHM SMD
AOT5B65M1
Alpha & Omega Semiconductor Inc.
IGBT 650V 5A TO220
STP16CP596B1R
STMicroelectronics
IC LED DRIVER LINEAR 50MA 24DIP
AD7895ANZ-2
Analog Devices Inc.
IC ADC 12BIT SAR 8DIP
MURB1620CTT4G
onsemi
DIODE ARRAY GP 200V 8A D2PAK
STGIPS30C60T-H
STMicroelectronics
MOD IPM SLLIMM 30A 600V 25SDIP
IXDN604SIA
IXYS Integrated Circuits Division
IC GATE DRVR LOW-SIDE 8SOIC
CY7C63743-SC
Infineon Technologies
IC MCU 8K LS USB/PS-2 24-SOIC
U2745B-MFBG3
Microchip Technology
RF TX IC UHF 310-440MHZ 16LSSOP
DSPIC30F4013T-30I/PT
Microchip Technology
IC MCU 16BIT 48KB FLASH 44TQFP
ADF4106BRUZ-RL
Analog Devices Inc.
IC CLK/FREQ SYNTH 16TSSOP
EL8403IS
Elantec
IC OPAMP GP 4 CIRCUIT 14SOIC
8A35001B-001AJG
Renesas Electronics America Inc
NETWORK TIMING
GRM0337U1HR90BD01D
Murata Electronics
CAP CER 0.9PF 50V U2J 0201
LT1356CS#PBF
Analog Devices Inc.
IC VOLTAGE FEEDBACK 2 CIRC 16SO
AON7280
Alpha & Omega Semiconductor Inc.
MOSFET N-CH 80V 20A/50A 8DFN
IRLI540N
Infineon Technologies
MOSFET N-CH 100V 23A TO220AB FP
VI-J6Z-MZ
Vicor Corporation
VI-J6Z-MZ 300V 2V 5A -

LMH6722MA
Texas Instruments
IC AMP CURRENT FEEDBACK 14SOIC
HZM6.8Z4MWATL-E
Renesas Electronics America Inc
TVS DIODE 3.5VWM 3MPAK
LM4041DIM7-1.2
Texas Instruments
IC VREF SHUNT 1% SC70-5
RT6200GE
Richtek USA Inc.
IC REG BUCK ADJ 600MA SOT23-6
R5F21274SNFP#X6
Renesas Electronics America Inc
IC MCU 16BIT 16KB FLASH 32LQFP
1N5227B
onsemi
DIODE ZENER 3.6V 500MW DO35
12102C472JAT2A
KYOCERA AVX
CAP CER 4700PF 200V X7R 1210
PZTA64
Fairchild Semiconductor
SMALL SIGNAL BIPOLAR TRANSISTOR,
XC1765ELSO8C
AMD
IC PROM SER C-TEMP 3.3V 8-SOIC
XR88C92CJ-F
MaxLinear, Inc.
IC UART FIFO DUAL 44PLCC
RT24C2X202
Bourns, Inc.
TRIMMER 2K OHM 0.75W PC PIN SIDE
DLW31SN900SQ2L
Murata Electronics
CMC 370MA 2LN 90 OHM SMD
LMK432F476ZM-T
Taiyo Yuden
CAP CER 47UF 10V Y5V 1812
MOC207R1VM
onsemi
OPTOISO 2.5KV TRANS W/BASE 8SOIC
GRM0335C1E390JD01D
Murata Electronics
CAP CER 39PF 25V C0G/NP0 0201
SE10PG-M3/84A
Vishay General Semiconductor - Diodes Division
DIODE GEN PURP 400V 1A DO220AA
RABS15M REG
Taiwan Semiconductor Corporation
BRIDGE RECT 1P 1KV 1.5A ABS-L
PI74LPT16245AEX
Diodes Incorporated
IC TXRX NON-INVERT 3.6V 48TSSOP